


Data cleaning is an essential step in business intelligence and data analysis because it validates accurate and reliable data. The accuracy of the data is vital to generate relevant information before being used in a data analysis or business intelligence (BI) process. The processed data helps businesses make informed data-driven decisions and improve business operations. Using unvalidated data can lead to inaccurate information that leads to misinformation, which can facilitate bad business decisions and faulty changes to existing processes.
Read more: Business Intelligence vs. Data Analytics
Featured partners
What is data cleaning?
Data cleaning is a necessary step that must occur before the data is executed in a data analysis process or business intelligence operation. Data cleaning involves looking for erroneous, inaccurate, or incomplete data that needs to be removed, corrected, or updated. Data cleaning consists of using AI tools and a manual review conducted by specific personnel to remove different types of incorrect or missing before any data can be processed in a business intelligence or data analysis process.
Read more: What is Data Analysis? A Guide to the Data Analysis Process
The importance of data quality
Using bad or poor data in a BI or data analysis process can lead to incorrect analysis, business operation errors, and bad business strategies. Addressing bad data before it’s executed in a data analysis process saves businesses money by reducing the expense of fixing bad data results after the data is processed, including the added cost of interrupting business operations to correct the results of bad data.
The cost of fixing poor data increases if it is not corrected in the data cleaning process. Cleaning bad data in the data cleaning process costs approximately one dollar. The cost increases tenfold if not corrected in the data cleaning phase, and if the bad data is processed and used, the cost of correcting a problem resulting from bad data increases to $100.
Data can be improperly formatted, contain spelling errors, duplicate records, missing values, integration errors, or outlier information that skews data. These types of data errors must be cleaned through a data cleansing process before data analysis processing. The emerging role of artificial intelligence (AI) and automation tools contribute significantly to identifying and correcting various errors in the data cleaning process, which enhances its overall efficiency.
Read more: Best Data Quality Software Guide
Understanding data cleaning
Data cleaning or washing is a critical step in the data processing phase because it boosts data consistency, correctness, and usability, making the data valuable after analysis. Ensuring the data is thoroughly cleaned can be challenging for businesses due to the varying formats and standards used. Data can come from different sources, which can be problematic in the data cleansing process.
For example, Lexical, grammatical, and misspelling errors can be challenging for businesses to correct, even when using advanced AI tools. Additionally, when integrity constraints are not applied to a data column in a table, the column can accept any value.
Embedded analytics data from an application populates a database table, providing the latest information for business uses without the need for querying. However, if an embedded value is populating a data column with no integrity constraints, then the software application populating the data column could populate the data column with incorrect information.
This is possible if a software application is updated and the embedded analytics data is incorrectly modified, sending erroneous data to the data column.
Outdated data that is not routinely updated can damage a business’s financials or reputation. Data quality issues can cause a company to lose up to 20% of its expected revenues. Without proper data hygiene, the saved data can contain misspellings, punctuation errors, improper parsing, and duplicate records. A lack of standardized naming conventions can also cause a business to lose expected revenues. To combat these data challenges, companies must continuously clean collected data to maintain data integrity and accuracy.
Read more: Common Data Quality Issues & How to Solve Them
How to clean data: A step-by-step guide
Data cleaning occurs after the data collection process is complete. Not all the collected data will be used, and it will most likely contain duplicates, erroneous values, missing values, and unformatted data that must be cleaned up before it is used in a business intelligence or data analysis process.
The emergence of AI tools minimizes the need to rely entirely on a manual data-cleaning process. However, there will be a requirement to manually check any AI tools used to ensure they identify and correct any discrepancies it’s expected to correct, which includes a final manual validation check that all errors are removed.
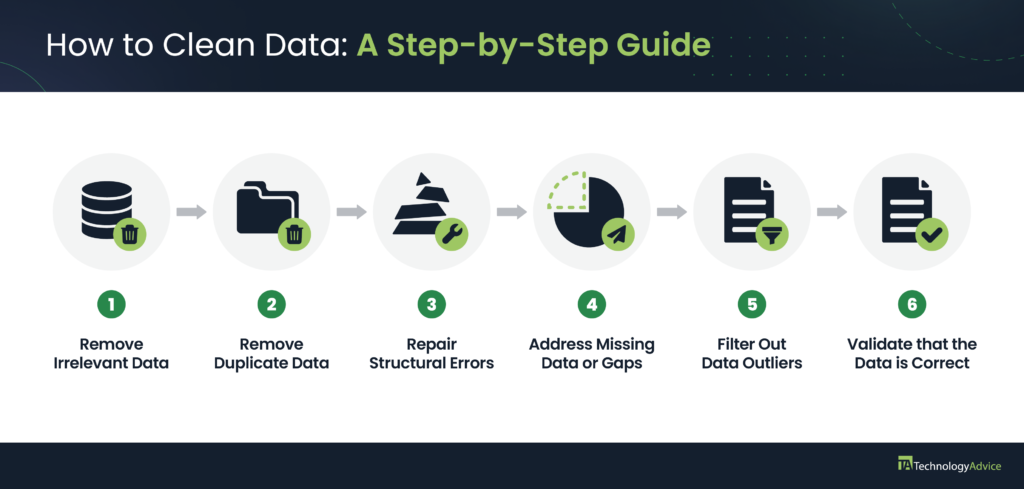
Step 1: Remove irrelevant data
Identify Unnecessary Data: Begin by reviewing your dataset to identify and remove any data that does not contribute to your analysis objectives. This could include columns or rows that are not relevant to the specific business questions or analysis goals you are addressing.
Criteria for Relevance: Establish clear criteria for what constitutes relevant data based on the purpose of your analysis. For instance, if you are analyzing customer data, fields like ‘customer ID’ and ‘purchase history’ might be relevant, while ‘middle name’ might not be.
Automation: Use AI tools to automate the identification of irrelevant data, but ensure you manually review the results to avoid excluding potentially useful information inadvertently.
Step 2: Deduplicate Redundant Data
Identify Duplicates: Scan your dataset for duplicate records, which are common in large datasets and can skew analysis results. Duplicates often occur when data is collected from multiple sources or entered manually multiple times.
Removal Process: Use automated tools to flag duplicate entries by comparing key identifiers like unique IDs or other distinguishing attributes. Once identified, remove or consolidate these duplicates.
Manual Review: After using AI tools, manually check a sample of the flagged duplicates to confirm accuracy and ensure that no unique data points are incorrectly removed.
Step 3: Repair Structural Errors
Identify Structural Issues: Look for inconsistencies in data structure, such as inconsistent naming conventions, formatting errors, or misplaced data. Common structural issues include typos, incorrect capitalization, and different date formats.
Correct Structural Errors: Use data-cleaning software or AI tools to standardize the structure across your dataset. For example, ensure that all dates follow a consistent format (e.g., YYYY-MM-DD) and that categorical data uses standardized labels.
Manual Inspection: Review the corrections made by the AI tools, especially in areas where human judgment is required to determine the correct format or structure.
Step 4: Address Missing Data
Identify Missing Data: Identify any gaps or missing values within your dataset, which could lead to biased or inaccurate analysis results. Missing data might be represented as blanks, ‘NaN’, or special characters like ‘?’.
Handling Strategies: Depending on the extent of the missing data, decide whether to remove the affected rows, fill them with a calculated value (e.g., mean, median), or use advanced techniques like imputation via AI models.
AI Assistance: Leverage AI tools that can intelligently predict and fill in missing data based on patterns within the dataset. However, ensure a final manual check is conducted to confirm the appropriateness of the AI-generated values.
Step 5: Filter Out Data Outliers
Detect Outliers: Outliers are data points that significantly deviate from the norm and can distort your analysis. Use statistical methods or AI algorithms to identify these anomalies.
Decide on Handling: Determine whether the outliers are errors that need correction, values that should be excluded, or important data points that should be kept (e.g., a significant sales spike).
Review Outliers: While AI can automate outlier detection, it’s important to manually review these points to ensure that valid data isn’t mistakenly removed.
Step 6: Validate That the Data Is Correct
Final Validation: Once the cleaning process is complete, conduct a thorough validation of the dataset to ensure all errors have been addressed. This includes running checks to confirm data consistency, accuracy, and completeness.
Manual Spot Checks: Perform random spot checks on the cleaned data to ensure the AI tools have correctly identified and rectified all issues. This step is crucial for maintaining data integrity.
Document the Cleaning Process: Keep detailed records of the cleaning steps you’ve taken, including any decisions made during the process. This documentation is important for transparency and reproducibility in future analyses.
Machine learning is the primary AI tool for identifying and correcting errors in a dataset. The ML algorithm can handle missing or inconsistent data, remove duplicates, and address outlier data saved in the dataset, provided it has learned to identify these errors during the ML algorithm testing phase by using either the supervised, unsupervised, or reinforcement learning process. The popularity of AI tools makes the data cleaning process more efficient, allowing businesses to focus on other aspects of the data analysis process.
Consider leveraging AI tools for data cleaning
Building on the strengths of machine learning in data cleaning, businesses can take a more proactive approach by leveraging AI tools to automate much of the grunt work involved. Implementing machine learning models not only helps in identifying and correcting data errors but also streamlines the entire cleaning process, from detecting inconsistencies to removing duplicates and spotting outliers. As these models learn and adapt from training data, they become more efficient over time, handling even complex cleaning tasks with greater accuracy.
To maximize the effectiveness of machine learning in data cleaning, it’s crucial to choose the right approach. Whether you opt for supervised, unsupervised, or reinforcement learning depends on the specific characteristics of your dataset and the type of errors you’re looking to resolve. Each method offers unique advantages, allowing for tailored solutions to your data challenges.
With AI taking over much of the data cleaning burden, your team can redirect its focus toward higher-level, strategic data analysis. This not only increases operational efficiency but also ensures that your cleaned data is more reliable, setting the stage for deeper insights and more informed business decisions.
Techniques and best practices for data cleaning
Data washing or cleaning has changed dramatically with the availability of AI tools. The traditional data cleansing method uses an interactive system like a spreadsheet that requires users to define rules and create specific algorithms to enforce the rules. The second method uses a systematic approach to remove duplicate data and data anomalies, ending in a human validation check.
With the challenges of cleaning big data, these traditional methods are impractical. Today, businesses use Extract, Transform, and Load (ETL) tools that extract data from one source and transform it into another form. The transformation step is the data cleaning process that removes errors and inconsistencies and detects missing information. After the transformation process is completed, the data is moved into a target dataset.
The ETL process cleans the data using association rules, which are if-then statements, statistical methods for error detection and established pattern-based data. With the emergence of AI tools, businesses save time with better results, though a human is still required to review the cleansed data.
The emerging role of Artificial Intelligence (AI) in data cleansing
Artificial Intelligence helps data cleaning by automating and speeding up the data cleansing process. Machine Learning (ML) is a subfield of AI. The ML algorithm uses computational methods to learn from the datasets it processes, and the ML algorithm will gradually improve its performance as it processes more sample datasets presented to the ML algorithm. The more sample data the ML code is exposed to, the better it becomes at identifying anomalies.
The ML algorithm uses supervised learning, which trains the algorithm based on sample input and output datasets labeled by humans. The second option is unsupervised learning, which allows the algorithm to find structure as it processes input datasets without human intervention. Reinforcement learning (RL) is another ML algorithm technique that uses trial and error to teach ML how to make decisions. Machine learning builds a model from sample data that allows the ML algorithm to automate decision-making based on the inputted dataset processed.
After ML algorithms have learned from sample datasets, the algorithm can correct the data using data imputation or interpolation methods to fill in missing values or labels. Imputation replaces missing data with an estimated value, and interpolation estimates the value of a data column by using a statistical method involving the values of other variables to guess the missing values. Both methods are used in ML to substitute missing values in a dataset. Data deduplication and consolidation methods are used to eliminate redundant data in a dataset.
Natural Language Processing (NLP) is another subfield of AI. It analyzes text and speech data. This AI tool can be used on text documents, speech transcripts, social media posts, and customer reviews. Natural Language Processing can extract data using an NLP model that can summarize a text, auto-correct a document, or be used as a virtual assistant.
In addition to the available AI tools used in BI and data analysis, mathematical and statistical equations complement the AI tools. These equations verify the AI results fall within an expected standard deviation. For example, numeric values that fall outside the expected standard deviation can be considered outliers and excluded from the dataset.
Read more: Data Analysis Methods and Techniques
When is a manual data cleaning process required?
Though manual data cleaning processes are still required, they are minimized. Manual data cleaning is needed when a business wants the data to be at least 98% accurate. The manual data cleaning effort focuses on correcting typos, standardizing formats, and removing outdated or duplicate data from the dataset. In business industries like healthcare or finance, manual data cleaning can enhance patient safety or help financial institutions minimize compliance risks. Manual data washing is essential when every record matters, and you want your dataset or database to be as perfect as possible.
Data validation and quality checks
A convenient method for ensuring data columns or fields contain valid data is to implement integrity constraints on the database table’s data column that the user must adhere to before the data is saved in a field. The integrity constraint is a set of rules for each data column that ensures the quality of information entered in a database is correct. The constraints include numeric values, alpha characters, a date format, or a field that must be a specific length before the data is saved in the field or data column. However, misspellings can be challenging to identify.
The integrity constraints will minimize some errors found during the data cleansing phase. A quality check performed by a human can validate correct spelling, outdated information, or outlier data still in the database. Quality checks can be routine or done before the data cleaning process occurs.
Data Profiling
Data profiling analyzes, examines, and summarizes information about source data to provide an understanding of the data structure, its interrelationships with other data, and data quality issues. This helps companies maintain data quality, reduce errors, and focus on recurring problematic data issues. The summary overview that data profiling provides is an initial step in formulating a data governance framework.
Normalization and standardization
Database normalization is a database design principle that helps you create database tables that are structurally organized to avoid redundancy and maintain the integrity of the database. A well-designed database will contain primary and foreign keys. The primary key is a unique value in a database table. A foreign key is a data column or field associated with a primary key in another table for cross-referencing the two tables.
A well-designed database table will be normalized to first (1NF), second (2NF), and third (3NF) normal forms. There are four, five, and six normal forms, but the third normal form is the furthest we will explore. The first normal form removes data redundancy from the database table.
Figure 1 contains redundant data, so the database table is not normalized to the 1st NF.
| Stud_ID | L_name | Major | Professor | Office_No |
| 1 | Jones | Info Sys | Perry | 2233 |
| 2 | Smith | Info Sys | Perry | 2233 |
| 3 | Thomas | Info Sys | Perry | 2233 |
| 4 | Hill | Info Sys | Perry | 2233 |
| 5 | Dunes | Info Sys | Perry | 2233 |
Unnormalized database tables cause insertion, deletion, and update anomalies. The insert anomaly will continually populate the table with unnecessary redundant data and overpopulate the database. The deletion anomaly can possibly unnecessarily delete the professor’s information if all the student information is removed. A related database table is lost when student data is deleted, and the database is not normalized to the 1st NF.
The last issue is an update anomaly. If another professor replaces Professor Perry, every record will be updated with the new professor’s information. Data redundancy requires extra space if not normalized, including the problems we just covered with insertions and deletions. To solve this problem, we must create two database tables, as shown in Figure 2.
The primary key is in a red font, and the foreign key uses a green font. The two database tables are now connected with the primary and foreign keys, and any professor information that changes will only require updating the professor table. These two databases are now considered to be in the first normal form.
Student Table
| Stud_ID | L_name | Major |
| 1 | Jones | Info Sys |
| 2 | Smith | Info Sys |
| 3 | Thomas | Info Sys |
| 4 | Hill | Info Sys |
| 5 | Dunes | Info Sys |
Professor Table
| Major | Professor | Office_No |
| Info Sys | Perry | 2233 |
| CompSci | Williams | 2214 |
The second normal form addresses removing partial dependency. A table must also be in 1NF to be in second normal form. A primary key is a unique value that retrieves one specific record from a database table, and the retrieved data columns or fields are functionally dependent on the primary key. For example, a unique student ID number can retrieve name, address, and other personal information. An essential concept of the second normal form is when the functional dependency relies on the primary key to retrieve specific data entirely dependent on the primary key.
In the Figure 3 tables, the three tables will help illustrate what partial dependency is.
| Stud_ID | L_name | Reg_no | Major | State |
| 1 | Jones | IS-1 | InfoSys | CA |
| 2 | Smith | IS-1 | InfoSys | HI |
| 3 | Thomas | CS-2 | CSE | NV |
| 4 | Hill | IS-1 | InfoSys | AZ |
| 5 | Dunes | IS-1 | InfoSys | TX |
Subject Table
| subject_ID | subject_name |
| 1 | InfoSys |
| 2 | CSE |
| 3 | Bus |
| 4 | Art |
Score Table
| score_ID | Stud_ID | subject_ID | Grade | Professor |
| 1 | 1 | 1 | 85 | Perry |
| 2 | 1 | 2 | 80 | Williams |
| 3 | 2 | 1 | 91 | Perry |
| 4 | 2 | 3 | 94 | Barnes |
| 5 | 2 | 4 | 88 | Knox |
| 6 | 3 | 2 | 79 | Williams |
The primary key retrieves functionally dependent information in the student and subject tables. The score_ID is not a good primary key because it only represents one test, and some students have taken more than one test. The score table uses a composite key comprising two or more columns as a primary key. The composite primary key can pull up a student’s tests. Since this is a score table, professors’ information is unnecessary, as it is partially dependent on subject_ID and has nothing to do with the student_ID.
Removing the professor column shown in Figure 3 puts the Figure 4 score table in second normal form, and adding a data column for the professor data in the subject table shown in Figure 4 also makes the table functionally dependent on the foreign key.
| score_ID | Stud_ID | subject_ID | Grade |
| 1 | 1 | 1 | 85 |
| 2 | 1 | 2 | 80 |
| 3 | 2 | 1 | 91 |
| 4 | 2 | 3 | 94 |
| 5 | 2 | 4 | 88 |
| 6 | 3 | 2 | 79 |
Subject Table
| subject_ID | subject_name | Professor |
| 1 | INfoSys | Perry |
| 2 | CSE | Williams |
| 3 | Bus | Barnes |
| 4 | Art | Knox |
Subject Table
| subject_ID | subject_name | Professor |
| 1 | INfoSys | Perry |
| 2 | CSE | Williams |
| 3 | Bus | Barnes |
| 4 | Art | Knox |
To illustrate transitive dependency, the score table adds two data columns, as shown in Figure 5.
| score_ID | Stud_ID | subject_ID | Grade | Test_name | Total_points |
| 1 | 1 | 1 | 85 | ||
| 2 | 1 | 2 | 80 | ||
| 3 | 2 | 1 | 91 | ||
| 4 | 2 | 3 | 94 | ||
| 5 | 2 | 2 | 88 | ||
| 6 | 3 | 4 | 79 |
The two data columns or fields added in Figure 5 will demonstrate how transitive dependency impacts a database table. The composite primary key can retrieve all the data columns except total points. The total points column depends on the test_name field, making it transitive-dependent and not associated with the composite primary key. The test_name field grades practical and presentation tests differently with a Pass or Fail rather than a standard multiple-choice test based on points. Removing the Test_name and Total_points fields from the score table and creating a test table will put the database tables in third normal form. See Figure 6 tables.
Score Table
| score_ID | Stud_ID | subject_ID | Grade | Test_name |
| 1 | 1 | 1 | 85 | |
| 2 | 1 | 2 | 80 | |
| 3 | 2 | 1 | 91 | |
| 4 | 2 | 3 | 94 | |
| 5 | 2 | 4 | 88 | |
| 6 | 3 | 2 | 79 |
Test Table
| Test_name | Total_points |
| Practical | |
| Quizzes | |
| Exams |
Data standardization is vital to the data cleansing process because it converts the structure of different datasets into a standard format after the data sources are collected and cleansed before being loaded into a target system for data processing. Using a standardized format makes it easier for the computer to process the data, improving its quality, accuracy, and reliability. Standardized data also makes it easier for businesses to compare and analyze the data to gain insight that improves overall business operations.
Establishing a data governance framework
A data governance framework should be the foundation of an effective and coherent data management program that establishes rules and procedures for proper data collection strategies, storage requirements, data quality, security, and compliance. Using a data enrichment tool as part of the governance framework can help businesses address outdated information, fill in missing information, and add more context to existing data.
- Data quality: The accuracy and organization of business data
- Data stewardships: Are problem solvers, creators, and protectors of the data
- Data security: Limit and restrict data access with security measures like biometrics and multi-factor authentication, including meeting any data compliance requirements
- Data management: Proper management of the data
Read more: 4 Data Enrichment Tools for Lead Generation
The four pillars of data governance ensure all stored data is usable, accessible, and protected, including reducing errors, inconsistencies, and discrepancies. Data governance also includes managing data catalogs, the central repositories that capture and organize metadata. The data catalog provides a comprehensive inventory of an organization’s data assets. Data governance has specific roles that delineate responsibilities.
- Data admin: Responsible for implementation of the data governance program and problem resolution
- Data steward: Responsible for executing data governance policies, overseeing data, and training new staff on policies
- Data custodian: Responsible for storing, retaining, and securing data governance policies, monitoring access, and securing data against threats
- Data owners: Employees in a company who are responsible for the quality of specific datasets
Data users are essential to help the organization accomplish its business goals by properly using the data. Building a data-conscious business culture must start with upper management and flow down through the organization through regular training, strategically placed posters promoting data governance and a comprehensive introduction of a data governance training program for new hires like the cybersecurity training program. Like cybersecurity training, data governance should be an annual training requirement.
Comprehensive data management software recommendations
There are aggregate BI solutions that perform the full spectrum of data analysis actions, like cleansing, analyzing, and interpreting data, allowing a business to make a data-informed decision. These comprehensive BI solutions also include data governance features that enable you to manage your data from inception to the proper disposal of obsolete data, allowing businesses to manage the entire data lifecycle.
IBM InfoSphere
IBM InfoSphere Master Data Management solution provides a tool that all businesses can use to manage data proactively with different deployment models and accelerate insights for quick decision-making.
Talend
Talend’s modern data management solution provides an end-to-end platform with data integration, data integrity and governance, and application and Application Programming Interface (API) integration.
Tibco
Tibco’s data management platform provides a master solution that allows users to manage, govern, and share data with peers. Tibco’s management solution features hierarchy management, role-specific applications, and data authoring.
Crucial data cleaning software features
Using business intelligence or data analysis tools without a thorough data cleansing process is a non-starter. Finding the best AI-based data cleansing software can be challenging with today’s various data cleaning applications. The best data cleaning software must have these features to thoroughly clean data expeditiously:
Data profiling and cleansing functionality
A data profile transformation lets a user examine the statistical details of the data structure, content, and integrity of the data. The data profiling feature uses rule-based profiling, including data quality rules, data profiling, and field profiling. This feature allows businesses to retrieve data stored in legacy systems and identify records with errors and inconsistencies while preventing the migration of erroneous data to the target database or data warehouse.
Advanced data quality checks
Data quality checks are rules or objects used in the information flow to monitor and report errors while processing data. These rules and objects are active during the data cleaning and help ensure data integrity.
Data mapping
Data mapping helps correctly map data from data sources to the correct target database during the transformation process. This feature provides a code-free, drag-and-drop graphical user interface that makes the process of mapping matching fields from one database to another database.
Comprehensive connectivity
A data cleansing tool must support the common source data formats and data structures, including XML, JSON, and Electronic Data Interchange (EDI), which allows the electronic exchange of business information between businesses using a standardized format.
Workflow automation
Workflow automation helps automate the entire data-cleaning process. This automation feature profiles incoming data, converts it, validates it, and loads it into a target database.
A data cleansing success story
Human Resource (HR) departments, including HR analytics, are critical to successful business operations. As discussed, data can be prone to errors and inconsistencies due to human error, data integration issues, and system glitches. Human resource departments contain employee records with Personally Identifiable Information (PII), which, if mishandled in any way, can damage a business financially, reputationally, operationally, and legally. IBM’s Cost of Data Breach Report in 2023 stated the average data breach cost was $4.45 million last year.
Using an AI data cleaning tool will improve the efficiency and consistency of the HR department’s data, and using a data cleansing guide that outlines each step in the process will help ensure success. La-Z-Boy understands the value of analytics and successfully used the Domo cloud-based management platform with advanced features like alerts that are triggered when a specific threshold is triggered, which causes a data custodian to perform a required action. Domo’s intuitive graphical dashboard displayed information that was easy to understand and take the appropriate action.
La-Z-Boy’s business intelligence and data manager understands that data analytics information begins with a repeatable data cleansing process. The repeatable process is the following:
- Identify the critical data fields
- Collect the data
- Remove duplicate values
- Resolve empty values
- Standardize the cleaning process using workflow automation
- Review, adapt, and repeat on a daily, weekly or monthly basis
In addition to HR analytics, Domo’s analytics software helps with pricing, SKU performance, warranty, and shipping for more than 29 million furniture variations.
The minutiae of data analysis
Every detail of the data analysis process should be considered critical. BI solutions come with advanced AI data cleansing tools that are only effective if they have been trained to look for specific discrepancies in data. Therefore, no matter how thoroughly you think the AI tool has cleaned the data, manually reviewing the AI-cleansed data is always recommended to ensure it did not miss a unique discrepancy the AI tool was not trained to address.
The data analysis phases before and after data washing are essential. Still, the most critical role is the data cleaning role because if any error is used to make a business decision, the mistake can range from negligible risks to catastrophic damages that can lead to business failure.
Negligible risks can include a poorly planned marketing campaign, an inability to pay suppliers or customer loss. To produce good data for decision-making, collecting and cleaning the correct data must be prioritized with attention to detail.
The data governance framework begins with validating the data quality before it’s saved in a database or data warehouse. These data integrity checks must be integrated into any application that saves data. Secondly, data governance should be as essential and given as much attention as cybersecurity training.


