


Key takeaways
Business intelligence (BI) software is a valuable tool that helps BI users make data-driven decisions. The quality of the data will determine the BI results that are used to make data-driven decisions, which means the data executed in BI software must be factual.
Included in this article are some best practice recommendations to ensure data quality.
Featured partners
What are the most common data quality issues?
Duplicated data that can be counted more than once or incomplete data are common data quality issues. Inconsistent formats, patterns, or data missing relationship dependencies can significantly impact BI results used to make informed decisions. Inaccurate data can also lead to bad decisions. Poor data quality can financially suffocate a business through lost profits, missed opportunities, compliance violations, and misinformed decisions.
What is data validation?
The two types of data that need to be validated are structured and unstructured data. Structured data is already stored in a relational database management system (RDBMS) and uses a set of rules to check for format, consistency, uniqueness, and presence of data values. Unstructured data can be text, a Word document, internet clickstream records from a user browsing a business website, sensor data, or system logs from a network device or an application that further complicates the validation process.
Structured data is easier to validate using built-in features in an RDBMS or a basic artificial intelligence (AI) tool that can scan comment fields. On the other hand, unstructured data requires a more sophisticated AI tool like natural language processing (NLP) that can interpret the meaning of a sentence based on the context.
Data Validation: When has it occurred
Data validation occurs when a data value is entered into a field and is checked to ensure it meets the field type conditions before being saved in a database or Excel spreadsheet. Data validation is a continual process that should happen before data is saved or anytime it’s extracted for further processing, especially if the data will be used to make business decisions.
How to do data validation testing
Initial data validation testing can be configured into a data field when a programmer creates the data fields in a business application. Whether you are developing an application or an Excel spreadsheet with data fields, the validation requirements can be built into the data field to ensure only specific data values are saved in each field. For example, a field type that can only accept numbers will not allow a data value to be saved if the data value has alphabets or special characters in the data value.
If an area code or zip code field contains all numbers but does not meet the length requirement, an error message will appear stating the data value must have three or five numbers before the data value is saved.
Ways to check data values
Here are the most common data validation checks:
⦁ Data type only: When a field only accepts numbers or alphabets as valid entries
⦁ Code check: Occurs when a drop-down list contains a finite number of items a person can select, like the mobile phone brand you own
⦁ Range check: Range checking can select a number from 1 to 10 for a customer service evaluation
⦁ Format check: Ensures the data value is entered according to the predefined format, like a social security number or a specific number of characters required in a field
⦁ Uniqueness check: Used when a data value cannot have duplicate values in a data field, such as a social security number with no identical numbers
⦁ Consistency checks: logically confirms step one occurring before step two
Natural language processing is used to examine unstructured data using grammatical and semantic tools to determine the meaning of a sentence. In addition, advanced textual analysis tools can access social media sites and emails to help discover any popular trends a business can leverage. With unstructured data being 80% of businesses’ data today, successful companies must exploit this data source to help identify customers’ purchasing preferences and patterns.
What are the benefits of data validation testing?
Validating data from different data sources initially eliminates wasted time, manpower and monetary resources, and ensures the data is compatible with the established standards. After the different data sources are validated and saved in the required field format, it’s easy to integrate into a standard database in a data warehouse. Clean data increase business revenues, promotes cost effectiveness, and provides better decision-making that helps businesses exceed their marketing goals.
What are some challenges in data validation?
Unstructured data lacks a predefined data model, so it’s more difficult to process and analyze. Although both have challenges, validating unstructured data is far more challenging than validating structured data. Unstructured data can be very unreliable, especially from humans who exaggerate their information, so filtering out distorted information can be time-consuming. Sorting, managing, and keeping unstructured data organized is very difficult in its native format, and the schema-on-read allows unstructured data to be stored in a database.
Extracting data from a database that has not been validated before the data is saved can be extremely time-consuming if the effort is manual. Even validated data extracted from a database still needs to be validated. Anytime large databases are extracted from multiple sources it can be time-consuming to validate the databases, and the process is compounded when unstructured data is involved. Still, the availability of AI tools makes the validation process easier.
ALSO READ: What is Data Visualization & Why is it Important?
Testing BI data using the Extract Transform and Load (ETL) process
The ETL process is used to ensure structured and unstructured data from multiple systems is verified as valid before it’s moved into a database or data warehouse that will be used by BI analytical software. Data cleaning removes data values that will not be transformed or associated with the database in a data warehouse. The transformation process involves converting the data into a format or schema that the BI software can use to derive deeper insight into the BI results that help management make informed decisions. See Figure one for a pictorial representation of a BI data pipeline.
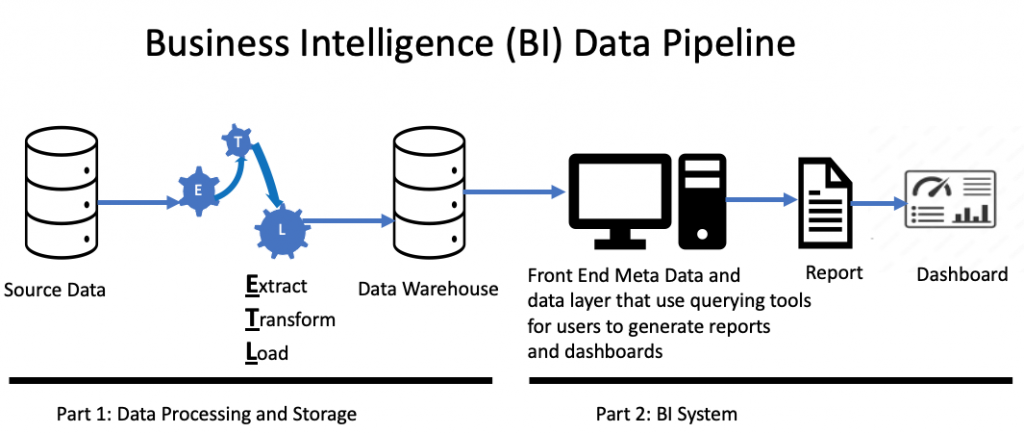
Figure 1.
Check the data at the source
The first part of the BI data pipeline is when all the validation checks occur. Checking structured data at the source is not a complicated process unless there is a large volume of structured data to check. Once unwanted data is removed from your structured data, RDBMS validation features check data values before it’s extracted from an RDBMS. For example, using the RDBMS structured query language (SQL) or Excel power query, you can easily remove duplicate records and any missing data values by creating a filter to check for blank fields. Checking the accuracy or relevancy of structured data can be done using AI tools, but it will still require human participation to verify the accuracy and relevance of the data. Hevo is one of several data cleaning software tools available on the market that can perform this action in the ETL process.
Cleaning unstructured data involves pulling data from multiple sources that may cause duplicate data if added to any structured or unstructured data. For example, an email address, a unique username, or a home address in unstructured data can be used to identify and remove duplicate data already in source data.
Check the data after the transformation
The transformation process aims to convert unstructured data into a usable storage format and merge it with similar data in the data warehouse. Structured data can have its database in a data warehouse or merge with another database in the warehouse. Unstructured data is a more complicated process because unstructured data needs to be converted into a readable format first. Data parsing converts unstructured data into a readable format for computers and saves it in a different format.
Grammar-driven or data-driven parsing techniques in a data parsing tool like ProxyScape can be used on unstructured data such as scripting languages, communication protocols, and social media sites. However, duplicate data removal, structural error repair, unwanted outliers by filtering, and missing data may still be required. In addition, businesses can use the BI results from this type of unstructured data to improve their network management processes or products and services sold to customers.
Verify the data load
The clean, extracted, and transformed data is loaded into target sources in the data warehouse for execution. The clean and extract process ensures the data is consistent, accurate, and error-free before execution. You can verify the data is correctly loaded by testing a small sample size of 50 records from each source as long as you know the results before the sample test is run. When you’ve tested four or five sample sizes, and the results are what you expect, you have an indication that the data is loaded correctly and is accurate and true.
Review the BI test results
Business intelligence test results are the basis for companies making smarter business decisions. An error in the BI results can occur anywhere along the BI data pipeline. The BI data pipeline starts with the source data that goes through the ETL process, which puts the validated data in the data warehouse. The data layer is what a user uses to create the BI report or dashboard. For example, a user generates BI results in a report and compares the results of a known sales revenue report saved in an Excel spreadsheet against the BI results.
A Business Intelligence testing strategy needs…
⦁ A test plan that covers different data scenarios such as no data, valid data, and invalid data
⦁ A method for testing
⦁ Specific tests that are query intensive with a variety of BI results to compare against known results saved in a spreadsheet, flat file, or database.
How should you address data quality issues?
The recommended method for addressing data quality issues is at the source. Any data saved in an RDBMS can be rejected if not entered into a field in the prescribed format. The format can be numeric, alphanumeric, or alphabets with assigned lengths. Text fields and unstructured data can be challenging, but AI tools are available to validate these character fields.
How important is data quality in Business Intelligence (BI) software?
The quality of your business data is equal to the quality of the business decisions you make. Making a business decision based on flawed data can lead to losing customers and eventually business revenues if bad data is not identified as the reason for the downward spiral. Like the foundation of a house, accurate business data is foundational for a successful business since the data is used to make business decisions.
As foundational data is the core of a business, organizations need to have established policies enforced through data quality measurements.
5 Attributes of Data Quality
⦁ Accuracy
⦁ Completeness
⦁ Reliability
⦁ Relevance
⦁ Timeliness
The importance of continual data verification
The purpose of verification checks is to make sure the validation process has successfully occurred. Verification occurs after data is migrated or merged into the data warehouse by running a scripted sample test and reviewing the BI results. The verification process is necessary because it checks the validation of all data fields, and sample BI test results can verify the data is validated by producing known results. Therefore, verification is a continual process that should occur throughout the entire BI data pipeline anytime a new data source is added or modified.
Looking fir the latest data quality software solutions? Check out our Data Quality Software Buyer’s Guide


